Turning Messy Prompts into Repeatable Reasoning Systems
December 2025 – Vicente Reig Rincón de Arellano
Key Takeaways
- Stop string-interpolating prompts. Use typed Signatures to define clear contracts between your app and the LLM—specify inputs, outputs, and docstrings that guide the model’s behavior.
- Separate the “what” from the “how.” Predictors like
Predict,ChainOfThought, andReActlet you swap reasoning strategies without rewriting your entire prompt. - Measure before you optimize. Evals give you a decision framework—ChainOfThought showed +3% improvement on faithfulness and coherence metrics compared to Predict in medical coding tasks.
- Ruby-first, batteries included. DSPy.rb ships with OpenTelemetry observability, tool-wielding agents, and prompt optimization out of the box.
Turning Messy Prompts into Repeatable Reasoning Systems
In a world that changes every other week
Vicente Reig, https://vicente.services
I am a consultant I help founders to solve the challenge of building and scaling reasoning systems.
Vicente Reig, https://vicente.services
(sounds like bee-then-te)
Hi, good evening everyone. Thank you for coming and having me today. It’s really cold out there and I appreciate everyone leaving the comfort of their homes and join us.
My name is Vicente. I am consultant helping founders to build AI workflows and agents that are predictable and easy to evolve.
Today, I am walking you through the tools and systems I use to build better products in a world where everything changes every other week.
export const generateEmailPrompt = ({ requesterName, sellerCompanyName, prospectName,
responsibilities, prospectTitle, successCriteria, reference, pains, gains, salesTip,
useCase, pitch }: EmailPromptParams) => {
return `
<context>
You are ${requesterName}, a sales enablement expert with deep understanding of Value Selling.
You work for ${sellerCompanyName}.
</context>
<style>
Use a warm conversational voice and tone. Use natural language appropriate for sales
prospecting. Ensure grammatically correct sentences.
</style>
<pitch>${pitch}</pitch>
<useCase>${useCase}</useCase>
<news>${reference}</news>
<pains>${pains}</pains>
<gains>${gains}</gains>
<responsibilities>${responsibilities}</responsibilities>
<successCriteria>${successCriteria}</successCriteria>
<tasks>
1. Compose a mobile friendly email highlighting how the pitch addresses ${prospectName}'s
responsibilities, pains, gains, and success criteria.
2. Create a personal connection in the first sentence.
3. The salutation must be informal.
4. Include a call to action as a P.S.
</tasks>
<output>
Sales tip: ${salesTip}
Your response must be valid json with "emailSubject" and "emailBody" keys.
Include no additional text, just the json:
{ "reasoning": "...", "emailSubject": "", "emailBody": "Hi...\\n\\nP.S. call to action" }
<emailSubject>
- no more than 5 words, tailored to individual, succinctly create anxiety
- must not contain emojis or special characters
</emailSubject>
<emailBody>
- use a 5th grade reading level, MUST be less than 100 words
- no more than 40 words per paragraph, no more than 9 words per sentence
- take less than 15 seconds to read, active voice, easy to scan
- Use 2 line breaks between paragraphs
- Each thought should be a new paragraph. Use forceful and decisive language.
- First paragraph: personal and relevant based on recent research
- Second paragraph: specific to fears and pain points
- Third paragraph: seller's value proposition (pitch) for a 5th grader
<callToAction>
- Do not ask for a meet or a time to chat
- Ask if it's worth learning more / Ask for their expert opinion / Clarify if priority
</callToAction>
</emailBody>
</output>
`};
Raise your hand if you’ve seen something like this in production. And don’t worry, it doesn’t fit on screen on purpose.
Now raise your hand if you’ve had to modify this when a new model came out. Or when your PM asked for a new feature. Or when the model started hallucinating last Tuesday.
This is the problem. Prompts are load-bearing infrastructure, and we treat them like a string concatenation problem.
and btw this is an actual prompt from a recent project I worked. Nevermind the typescript/
What if there was a better way to work with prompts?
What if we modeled prompts after functions?
f(x) = y
Input types. Output types. Testable. Composable.
You define what goes in. You define what comes out. The framework handles the rest. You detach yourself from the nuances of dealing with an LLM.
You can compose prompts into workflows. You can start modeling and evolving your products using a higher level vocabulary.
This is the core idea behind the DSPy Paradigm. DSPy stands for: Declarative Self-Improving Python, which I’ve reframed from a Ruby perspective.
From now on we are gonna be referring as these functions as Signatures.
A Contract between you and your LLM
# Before: String interpolation
prompt = "Summarize this text: #{text}. Keep it to 2-3 sentences..."
# After: Typed contract
class SummarizeTask < DSPy::Signature
description "Summarize text concisely while preserving key concepts"
input do
const :text, String
end
output do
const :summary, String, description: 'Keep it to 2-3 sentences'
end
end
DSPy.configure do |c|
c.lm = DSPy::LM.new('claude-opus-4-5-20251101', api_key: ENV['ANTHROPIC_API_KEY'])
end
summarizer = DSPy::Predict.new(SummarizeTask)
summarizer.call(text: 'In a place in La Mancha, whose name I do not wish to remember...').summary
We lived in a world where we’d manually write these monolithic prompts.
Now, we can write the contract that governs the relationship between your app and the LLM. You describe the goal of the task, how you are going to provide the necessary information to complete it, and how you want it back.
The framework compiles this into a prompt. So you never write them manually ever again. You get automatic input validations and structured outputs via Sorbet Types. (and few more things OOTB that we will see later)
When the models change, your contract stays the same. Or when the prompting technique change, the compiled prompt adapts.
[pointing at slides] so what happens when want better summaries?
Better Summaries!
One Signature, Two Predictors
# Same contract, different strategies
predict = DSPy::Predict.new(Summarize)
cot = DSPy::ChainOfThought.new(Summarize) # adds reasoning output field
# Both produce the same output type
article = 'In a place in La Mancha, whose name I do not wish to remember...'
predict.call(text: article).summary # => String
cot.call(text: article).summary # => String
cot.call(text: article).reasoning # => String (bonus)
Same Signature. Different strategies. Same typed output.
You learn that Chain of Thought is a good and simple technique to improve the results.
We can compare how the same contract performs under different prompting techniques.
Predict goes straight to the answer. ChainOfThought adds a reasoning step.
And we can run one after the other and compare them. Now is it better?
Now, is it better for real?
(heckler in the background) Aren’t we just vibing all this?
The truth is that we really don’t know!
What are we gonna do test it in production? We can do better!
That’s where Evals come in.
Are these Summaries any good? (1/4)
Evals as a Decision Framework
class EvaluateSummary < DSPy::Signature
description "Evaluate summary quality"
input do
const :grounded_summary, GroundedSummary
const :mindset, EvaluatorMindset
end
output do
const :faithfulness, Integer,
description: "Score 1-5: factually accurate?"
const :relevance, Integer,
description: "Score 1-5: captures key info?"
const :coherence, Integer,
description: "Score 1-5: well-structured?"
const :fluency, Integer,
description: "Score 1-5: readable?"
end
end
class EvaluatorMindset < T::Enum
enums do
Critical = new('critical')
Balanced = new('balanced')
Generous = new('generous')
end
end
class GroundedSummary < T::Struct
const :source_text, String
const :summary, String
end
We rolled out our sleeves and wrote another Signature. We can model the prompt and the context using plain Ruby structures.
An evaluating function takes the summary we generated alongside the original text, and we ask it to evaluate it using the 5 dimensions of the G-Eval framework.
Now we’ve got something we can work with.
Which predictor is better?
Let’s do a quick poll first!
- Who thinks Chain of Thought produces better output? [Wait for hands]
- Who thinks just asking for the straight answer is better? [Wait for hands]
Alright, how do we measure quality?
Are these Summaries any good? (2/4)
Metrics
def create_judge_metric
judge = DSPy::ChainOfThought.new(EvaluateSummary)
->(_example, prediction) do
evaluation = judge.call(
grounded_summary: prediction.grounded_summary,
mindset: EvaluatorMindset::Critical,
)
{
passed: evaluation.overall_score >= 3.5,
score: evaluation.overall_score / 5.0, # Normalize to 0-1
faithfulness: evaluation.faithfulness,
# ...
}
end
end
LLMs judging free form text
We need a metric to score the result.
In defining these metrics is where the teams spend a good chunk of the effort.
There’s no one metric to rule them all. It really depends on the problem you are solving.
Some examples:
- we are using an LLM as a Judge here to evaluate free form text.
- LLMs shine when classifying unstructured information. In that case we’d use accuracy, precision and recall.
Are these Summaries any good? (3/4)
Metrics
llm_judge_metric = create_judge_metric
articles = [ ... ]
# Evaluate Predict
puts "Evaluating DSPy::Predict..."
predict = DSPy::Predict.new(Summarize)
predict_evaluator = DSPy::Evals.new(predict, metric: llm_judge_metric)
predict_metrics = predict_evaluator.evaluate(articles)
# Evaluate ChainOfThought
puts "Evaluating DSPy::ChainOfThought..."
cot = DSPy::ChainOfThought.new(Summarize)
cot_evaluator = DSPy::Evals.new(cot, metric: llm_judge_metric)
cot_metrics = cot_evaluator.evaluate(articles)
print_results(predict_metrics, cot_metrics)
A natural sequence of low-risk and reversible decisions.
Evals guide your team’s course of action, informing next steps in the development.
What I really like is that they introduce planned decision checkpoints. A sequence of low-risk and reversible decisions. The cool thing is that they create opportunities to reassess and change course as needed.
They tie everything together: Predictor, examples, metric in a single API. You can run both approaches through the same evaluator. Compare the numbers.
Alright, let’s take a look at the results!
Are these Summaries any good? (4/4)
The Results
Overall Scores
Predict: 93.0%
ChainOfThought: 96.0%
---
Improvement: +3.0 pts
Per Dimension
| Dimension | Delta |
|---|---|
| Faithfulness | +0.4 |
| Coherence | +0.2 |
| Relevance | +0.0 |
| Fluency | +0.0 |
CoT wins on faithfulness and coherence. Now you know.
CoT barely wins. The interesting part: it wins on faithfulness and coherence. Not relevance or fluency. So there’s a trade off for y’all there to make. Now you know.
The real win isn’t the number. It’s that you can measure it.
Now I mentioned DSPy.rb came with a few tools out of the box.
Batteries Included 1/3
Built-in Observability
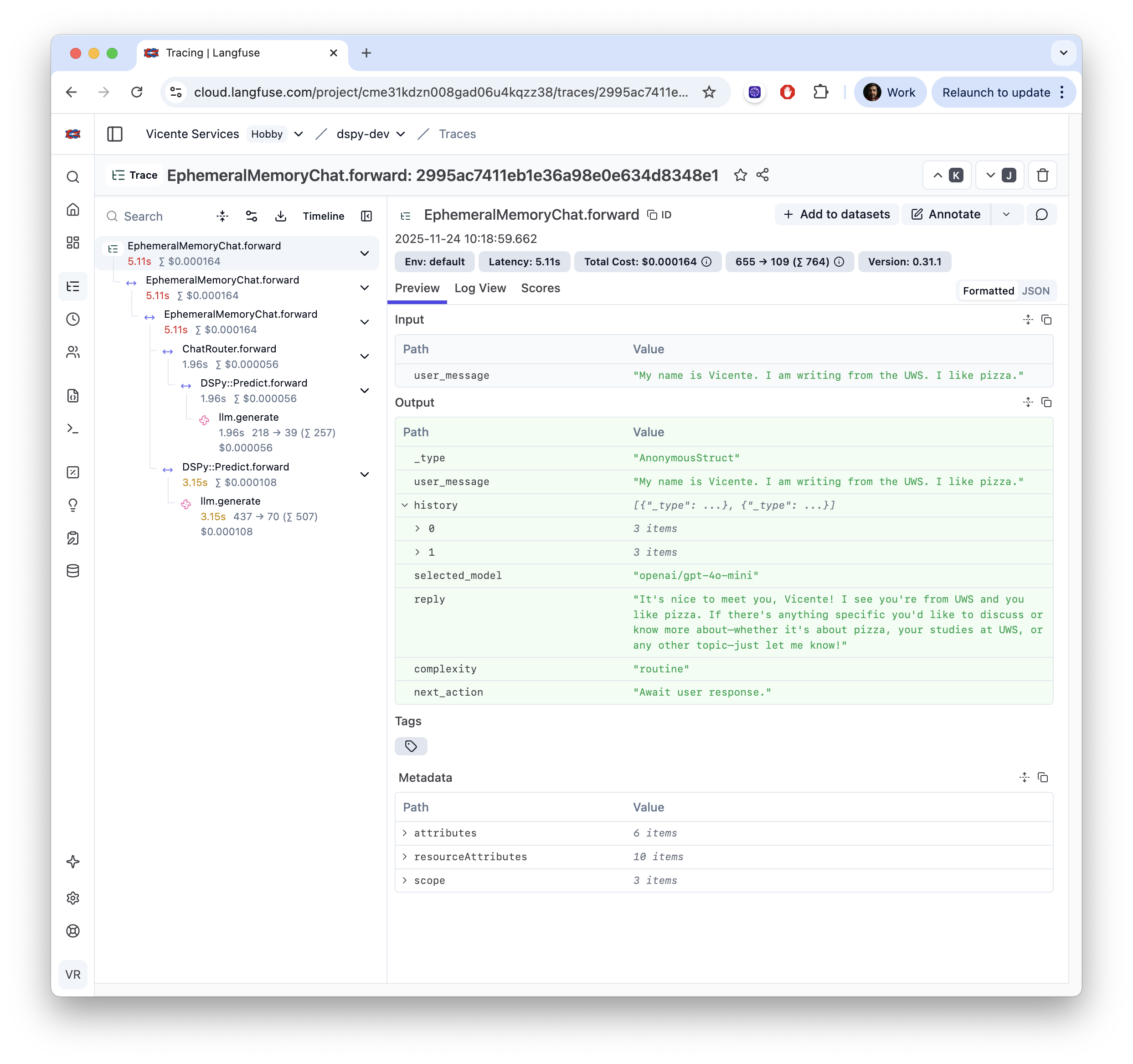
Because you don’t need Neo’s Matrix Vision to understand what is going in production, observability is one of those.
Every call is traced with any Open Telemetry sink like Langfuse in here.
When something breaks in production, you can see exactly which LLM call failed, review inputs, outputs, costs and response times.
Batteries Included 2/3
Tool wielding agentic loops
require 'dspy'
DSPy.configure do |c|
c.lm = DSPy::LM.new('openai/gpt-4o-mini', api_key: ENV['OPENAI_API_KEY']) # global
end
research_agent = DSPy::ReAct.new(ResearchAssistant, tools: [
WebSearchTool.new,
CalculatorTool.new,
DataAnalysisTool.new
])
research_agent.configure do |c|
c.lm = DSPy::LM.new('anthropic/claude-opus-4-5-20251101', api_key: ENV['ANTHROPIC_API_KEY'])
end
result = research_agent.call(
topic: "Heating up frozen pork buns with a Dutch oven",
depth: ResearchDepth::Detailed
)
puts "Summary: #{result.summary} Confidence: #{result.confidence}"
DSPy.rb comes with three core Predictors, so you have a place to start. They are your workflows and agents building blocks.
We will cover ReAct in a separate talk. In the meantime, you can visit the project’s blog where I am walking through a bunch of examples!
Batteries Included 3/3
Let the Model Write Your Prompts
class ADETextClassifier < DSPy::Signature
description "Determine if a clinical sentence describes an adverse drug event (ADE)"
input { const :text, String }
output { const :label, ADELabel }
end
# config/optimized_prompts/mipro_v2/20250721112200_ade_text_classifier.txt
- Determine if a clinical sentence describes an adverse drug event (ADE)
+ Evaluate the provided clinical sentence and classify it as describing an adverse
+ drug event (ADE) by identifying key indicators of negative drug reactions. Assign
+ a label of '1' for adverse events and '0' for cases without adverse effects. Be
+ thorough in your analysis, considering the context of medications and pre-existing
+ health issues.
Accuracy : +3.33 pp
Precision: +4.17 pp
Recall : +6.67 pp
F1 Score : +5.13 pp
Last but not least: I said you’d never write a prompt again!
Now we can leverage Evals to let the models optimize our prompts. Once you’ve defined your metrics, you can steer the model in improving your prompts.
This piece is adapted from a classifier project I worked in the past as well.
The MVC Moment for AI
in a world where everything changes.
<div class="text-4xl mb-4">Signatures</div>
<div class="text-gray-400">Contracts that survive model changes</div>
<div class="text-4xl mb-4">Predictors</div>
<div class="text-gray-400">Strategies you can swap</div>
<div class="text-4xl mb-4">Evals</div>
<div class="text-gray-400">Decisions you can measure</div>
gem install dspy
We have seen Contracts that survive model changes. Strategies you can swap. Decisions you can measure. Prompts that self-improve.
20 years ago the Model View Controller Architecture gave us structure to build web apps and web services. The DSPy Paradigm gives us today the structure for AI.
Thank you all for your time.

Happy to take questions if there’s time!