Turning Messy Prompts into Repeatable Reasoning Systems
In a world that changes every other week
Vicente Reig, https://vicente.services
I am a consultant I help founders to solve the challenge of building and scaling reasoning systems.
Vicente Reig, https://vicente.services
(sounds like bee-then-te)
export const generateEmailPrompt = ({ requesterName, sellerCompanyName, prospectName,
responsibilities, prospectTitle, successCriteria, reference, pains, gains, salesTip,
useCase, pitch }: EmailPromptParams) => {
return `
<context>
You are ${requesterName}, a sales enablement expert with deep understanding of Value Selling.
You work for ${sellerCompanyName}.
</context>
<style>
Use a warm conversational voice and tone. Use natural language appropriate for sales
prospecting. Ensure grammatically correct sentences.
</style>
<pitch>${pitch}</pitch>
<useCase>${useCase}</useCase>
<news>${reference}</news>
<pains>${pains}</pains>
<gains>${gains}</gains>
<responsibilities>${responsibilities}</responsibilities>
<successCriteria>${successCriteria}</successCriteria>
<tasks>
1. Compose a mobile friendly email highlighting how the pitch addresses ${prospectName}'s
responsibilities, pains, gains, and success criteria.
2. Create a personal connection in the first sentence.
3. The salutation must be informal.
4. Include a call to action as a P.S.
</tasks>
<output>
Sales tip: ${salesTip}
Your response must be valid json with "emailSubject" and "emailBody" keys.
Include no additional text, just the json:
{ "reasoning": "...", "emailSubject": "", "emailBody": "Hi...\\n\\nP.S. call to action" }
<emailSubject>
- no more than 5 words, tailored to individual, succinctly create anxiety
- must not contain emojis or special characters
</emailSubject>
<emailBody>
- use a 5th grade reading level, MUST be less than 100 words
- no more than 40 words per paragraph, no more than 9 words per sentence
- take less than 15 seconds to read, active voice, easy to scan
- Use 2 line breaks between paragraphs
- Each thought should be a new paragraph. Use forceful and decisive language.
- First paragraph: personal and relevant based on recent research
- Second paragraph: specific to fears and pain points
- Third paragraph: seller's value proposition (pitch) for a 5th grader
<callToAction>
- Do not ask for a meet or a time to chat
- Ask if it's worth learning more / Ask for their expert opinion / Clarify if priority
</callToAction>
</emailBody>
</output>
`};
What if we modeled prompts after functions?
f(x) = y
Input types. Output types. Testable. Composable.
A Contract between you and your LLM
# Before: String interpolation
prompt = "Summarize this text: #{text}. Keep it to 2-3 sentences..."
# After: Typed contract
class SummarizeTask < DSPy::Signature
description "Summarize text concisely while preserving key concepts"
input do
const :text, String
end
output do
const :summary, String, description: 'Keep it to 2-3 sentences'
end
end
DSPy.configure do |c|
c.lm = DSPy::LM.new('claude-opus-4-5-20251101', api_key: ENV['ANTHROPIC_API_KEY'])
end
summarizer = DSPy::Predict.new(SummarizeTask)
summarizer.call(text: 'In a place in La Mancha, whose name I do not wish to remember...').summary
Better Summaries!
One Signature, Two Predictors
# Same contract, different strategies
predict = DSPy::Predict.new(Summarize)
cot = DSPy::ChainOfThought.new(Summarize) # adds reasoning output field
# Both produce the same output type
article = 'In a place in La Mancha, whose name I do not wish to remember...'
predict.call(text: article).summary # => String
cot.call(text: article).summary # => String
cot.call(text: article).reasoning # => String (bonus)
Same Signature. Different strategies. Same typed output.
Now, is it better for real?
(heckler in the background) Aren’t we just vibing all this?
Are these Summaries any good? (1/4)
Evals as a Decision Framework
class EvaluateSummary < DSPy::Signature
description "Evaluate summary quality"
input do
const :grounded_summary, GroundedSummary
const :mindset, EvaluatorMindset
end
output do
const :faithfulness, Integer,
description: "Score 1-5: factually accurate?"
const :relevance, Integer,
description: "Score 1-5: captures key info?"
const :coherence, Integer,
description: "Score 1-5: well-structured?"
const :fluency, Integer,
description: "Score 1-5: readable?"
end
end
class EvaluatorMindset < T::Enum
enums do
Critical = new('critical')
Balanced = new('balanced')
Generous = new('generous')
end
end
class GroundedSummary < T::Struct
const :source_text, String
const :summary, String
end
Which predictor is better?
Predict?
ChainOfThought?
?
Are these Summaries any good? (2/4)
Metrics
def create_judge_metric
judge = DSPy::ChainOfThought.new(EvaluateSummary)
->(_example, prediction) do
evaluation = judge.call(
grounded_summary: prediction.grounded_summary,
mindset: EvaluatorMindset::Critical,
)
{
passed: evaluation.overall_score >= 3.5,
score: evaluation.overall_score / 5.0, # Normalize to 0-1
faithfulness: evaluation.faithfulness,
# ...
}
end
end
LLMs judging free form text
Are these Summaries any good? (3/4)
Metrics
llm_judge_metric = create_judge_metric
articles = [ ... ]
# Evaluate Predict
puts "Evaluating DSPy::Predict..."
predict = DSPy::Predict.new(Summarize)
predict_evaluator = DSPy::Evals.new(predict, metric: llm_judge_metric)
predict_metrics = predict_evaluator.evaluate(articles)
# Evaluate ChainOfThought
puts "Evaluating DSPy::ChainOfThought..."
cot = DSPy::ChainOfThought.new(Summarize)
cot_evaluator = DSPy::Evals.new(cot, metric: llm_judge_metric)
cot_metrics = cot_evaluator.evaluate(articles)
print_results(predict_metrics, cot_metrics)
A natural sequence of low-risk and reversible decisions.
Are these Summaries any good? (4/4)
The Results
Overall Scores
Predict: 93.0%
ChainOfThought: 96.0%
---
Improvement: +3.0 pts
Per Dimension
| Dimension | Delta |
|---|---|
| Faithfulness | +0.4 |
| Coherence | +0.2 |
| Relevance | +0.0 |
| Fluency | +0.0 |
CoT wins on faithfulness and coherence. Now you know.
Batteries Included 1/3
Built-in Observability
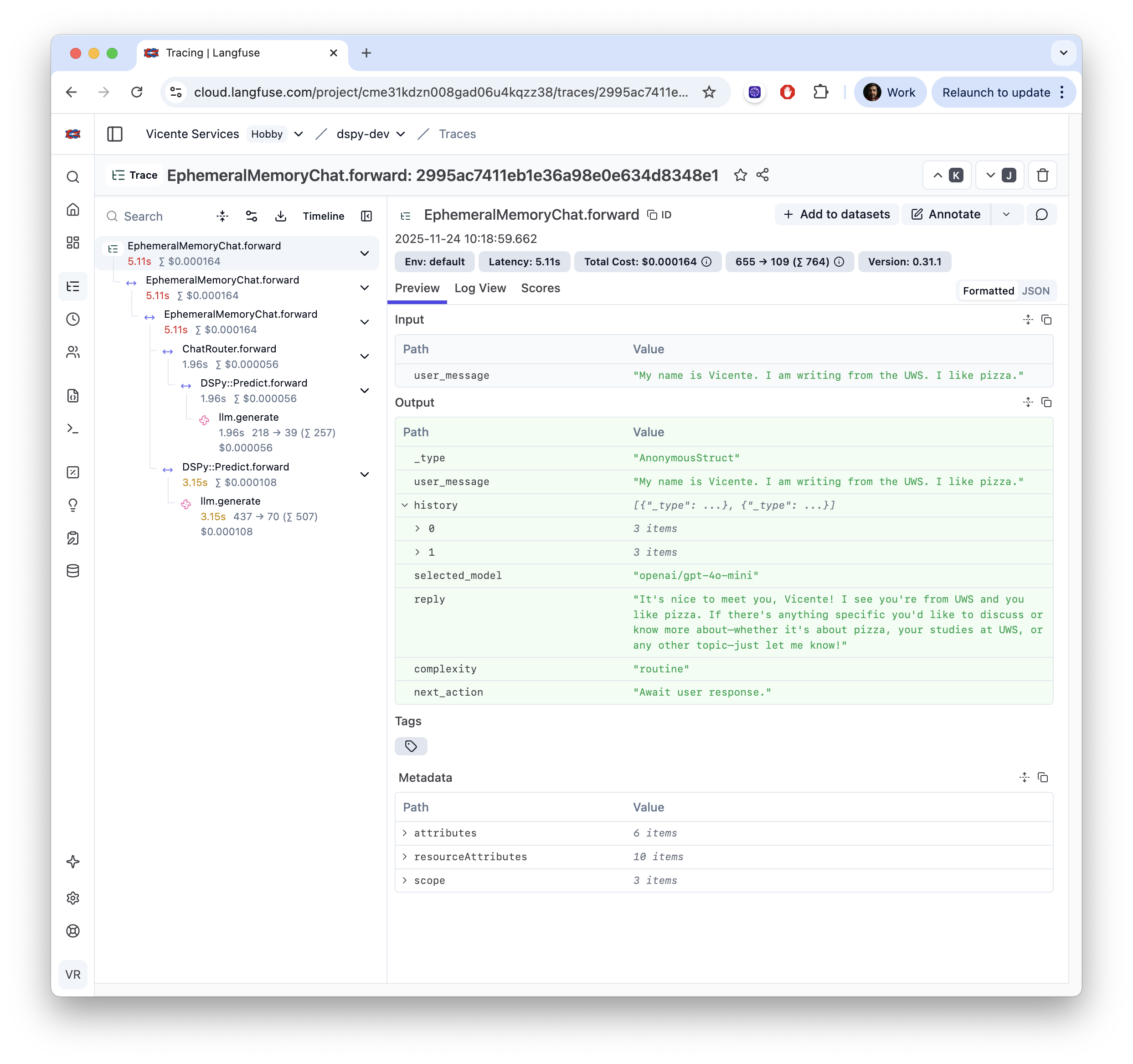
Batteries Included 2/3
Tool wielding agentic loops
require 'dspy'
DSPy.configure do |c|
c.lm = DSPy::LM.new('openai/gpt-4o-mini', api_key: ENV['OPENAI_API_KEY']) # global
end
research_agent = DSPy::ReAct.new(ResearchAssistant, tools: [
WebSearchTool.new,
CalculatorTool.new,
DataAnalysisTool.new
])
research_agent.configure do |c|
c.lm = DSPy::LM.new('anthropic/claude-opus-4-5-20251101', api_key: ENV['ANTHROPIC_API_KEY'])
end
result = research_agent.call(
topic: "Heating up frozen pork buns with a Dutch oven",
depth: ResearchDepth::Detailed
)
puts "Summary: #{result.summary} Confidence: #{result.confidence}"
Batteries Included 3/3
Let the Model Write Your Prompts
class ADETextClassifier < DSPy::Signature
description "Determine if a clinical sentence describes an adverse drug event (ADE)"
input { const :text, String }
output { const :label, ADELabel }
end
# config/optimized_prompts/mipro_v2/20250721112200_ade_text_classifier.txt
- Determine if a clinical sentence describes an adverse drug event (ADE)
+ Evaluate the provided clinical sentence and classify it as describing an adverse
+ drug event (ADE) by identifying key indicators of negative drug reactions. Assign
+ a label of '1' for adverse events and '0' for cases without adverse effects. Be
+ thorough in your analysis, considering the context of medications and pre-existing
+ health issues.
Accuracy : +3.33 pp
Precision: +4.17 pp
Recall : +6.67 pp
F1 Score : +5.13 pp
The MVC Moment for AI
in a world where everything changes.
<div class="text-4xl mb-4">Signatures</div>
<div class="text-gray-400">Contracts that survive model changes</div>
<div class="text-4xl mb-4">Predictors</div>
<div class="text-gray-400">Strategies you can swap</div>
<div class="text-4xl mb-4">Evals</div>
<div class="text-gray-400">Decisions you can measure</div>
gem install dspy

1 / 17